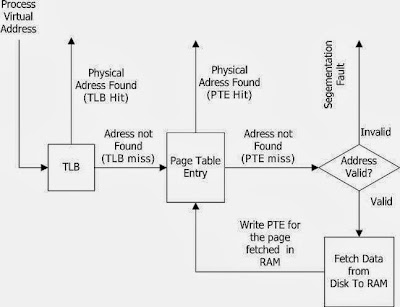
How malloc works in userspace
I was checking how malloc work as compared to kernel kmalloc in term of physical memory allocation.What I found as below.. Glibc/C libary implement the malloc implementation, For memory less than 128kb use brk()/sbrk more than that use mmap with MAP_PRIVATE|MAP_ANONYMOUS for test ran a small program on userspace I wrote void main() { int *a; a =(int*)malloc(150*1024); /* mmap invocation */ //a =(int*)malloc(10); /* brk invocation */ } and ran strace on the o/p, there I can see brk and mmap invocation.What I understood from brk call.It increases the data section (Thr Brk limit) and add the memory to malloc.In mmap anonymous private pages are allocated by kernel and added as one vma section of process address space,From there glibc allocate memory and give it to malloc. more details : Link1 Link2 Link3 bestone__ Best_link